04
Dec 2019
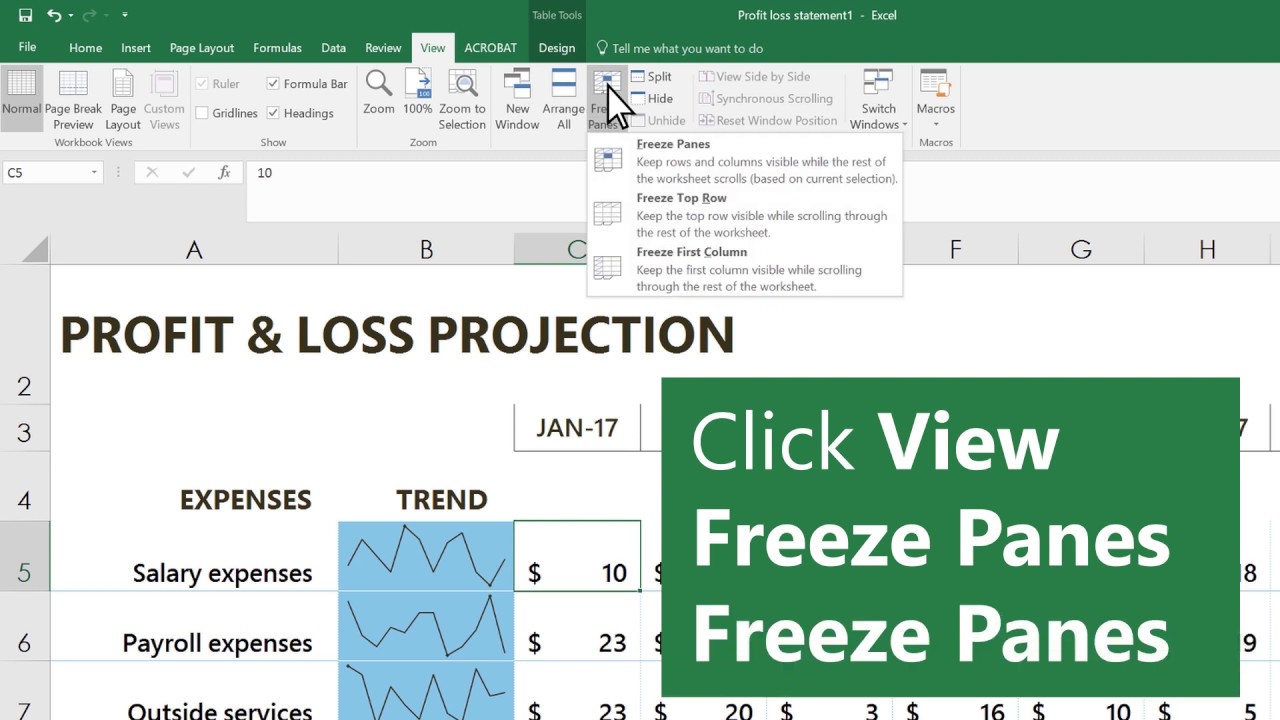
Freeze columns or rows in Microsoft Excel
To keep an area of a worksheet visible while you scroll to another area of the worksheet in Microsoft Excel, go to the View tab, where you can Freeze Panes to lock specific rows and columns in place, or you can Split panes to create separat...